Main Page: Difference between revisions
| Line 83: | Line 83: | ||
# At the end you can run annotation as your choice. | # At the end you can run annotation as your choice. | ||
==== | ==== PrimeView importing failed on v4.3.0 beta1 (R 2.14.x) ==== | ||
# Go to http://www.bioconductor.org/packages/2.11/data/annotation/html/primeviewcdf.html and click on the link for the windows binary package "primeviewcdf_2.11.0.zip" and download the zipped package. | |||
# Unzip the downloaded package and put the entire package folder "primeviewcdf" under your R2.14.2 library folder (default C:\Program Files\R\R-2.14.2\library). | |||
However, you cannot run Affymetrix annotation using bioconductor annotation packages at the end of importing, because the annotation package for primeview array is not available at bioconductor. Another commonly use annotation database, SOURCE, has also been down these days. Instead you need to import your own annotation into BRB-ArrayTools. Here is what you can do, | |||
# Download the primeview annotation file in CSV format from Affymetrix website (https://www.affymetrix.com/user/login.jsp?toURL=/support/file_download.affx?onloadforward=/analysis/downloads/na32/ivt/PrimeView.na32.annot.csv.zip). | |||
# Open the CSV format file in Excel and then save it as a tab-delimited .txt file. | |||
# Import your data in CEL file format into BRB-ArrayTools through Data Import Wizard. During importing, you need to check the option "Import your own identifiers file to annotate your data" at the "Probe Set Id options" page, and then Click on "OK". At the next dialog form you need to select the radio button "The identifiers are stored in a separate file" and browse for the tab-delimited file you just saved. The head line # for this file is 25. Then you need to select the corresponding gene identifiers column headers. You need to check the box "Annotate the project with these gene ids, instead of using the data from SOURCE database" before proceeding to the next page. | |||
==== Gene ST 1.1 ==== | |||
=== Annotation === | === Annotation === | ||
Revision as of 15:55, 30 November 2012
Your friend to BRB-ArrayTools .
Features
Import from multiple data types
Expression data, Illumina methylation data, Copy number data (CGH-Tools), RNA-Seq count data processed through Galaxy web tool.
Sophisticated statistical analysis tools
Class comparison for differential expression, class prediction, graphical 2d and 3D interactive plots, gene set analysis, and more.
Comprehensive biological annotations
Gene ontology, pathways, protein domain, broad msigdb, lymphoid signatures, experimentally verified transcription factor targets, computationally predicted microRNA targets.
Screenshots
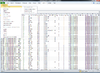 BRB-ArrayTools graphical user interface
BRB-ArrayTools graphical user interface

 Heatmap and dendrogram generated from the Pomeroy sample dataset.
Heatmap and dendrogram generated from the Pomeroy sample dataset.

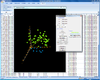 Interactive MDS plot of samples from running the multidimensional scaling analysis on the Pomeroy dataset.
Interactive MDS plot of samples from running the multidimensional scaling analysis on the Pomeroy dataset.

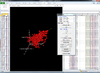 Interactive 3D scatterplot of genes on the Pomeroy dataset.
Interactive 3D scatterplot of genes on the Pomeroy dataset.

X-axis is from array 'Brain_MD_1', y-axis is 'Brain_MD_2' and z-axis is 'Brian_MD_3'.
 Interactive 2D scatterplot of samples with gene annotation from a selected gene using right click menu.
Interactive 2D scatterplot of samples with gene annotation from a selected gene using right click menu.

The right click menu gives an option to highlight up/down-regulated genes, export gene list, copy plot to clipboard, highlight genes in gene set, link genes among plots and change properties of the plot like title, point size, color of points, fold change threshold for up/down regulated genes.
 Interactive volcano plot from the output of running a class comparison tool.
Interactive volcano plot from the output of running a class comparison tool.

When you move mouse over a gene (point), the gene unique ID and/or symbol will be popped up.
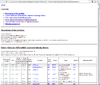 HTML output of running the class comparison analysis.
HTML output of running the class comparison analysis.

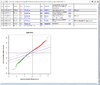 HTML output containing SAM plot from running the significance of microarray analysis.
HTML output containing SAM plot from running the significance of microarray analysis.

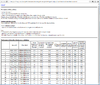 HTML output of running the class prediction analysis.
HTML output of running the class prediction analysis.

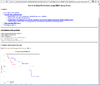 HTML output of running the survival risk analysis.
HTML output of running the survival risk analysis.

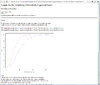 Result of sample size analysis.
Result of sample size analysis.

FAQs
General
How to install BRB-ArrayTools if you have 64-bit MS-Office?
There is no difference in terms of the installation.
If installation, I can not find the BRB-ArrayTools in Windows > Start > All Programs.
Check EXCEL. ArrayTools and CGHTools are under the menu of Addon.
Can I upgrade R or install multiple versions of R?
Better not for upgrading. Installing multiple versions of R is OK provided you know some details described below.
Each version of BRB-ArrayTools has been tested with a certain version of R. So there maybe a compatibility problem with certain functions used in the code if you decide to upgrade R.
- BRB-ArrayTools (up to v4.2.1) requires StatconnDCOM which means the following conditions have to be satisfied:
- R needs to registered in the Windows's registry (it should be done if you accept all default options when R was installed).
- The R package 'rscproxy' has to be installed under the library folder the registered R. It cannot be installed under user's Document's folder as other R's packages.
- BRB-ArrayTools (from v4.3.0) requires Rserve package. That means
- Rserve has to be installed. It does not have to be installed under R\library folder.
- Rserve.exe from R\librar\Rserve\inst\i386 and x64 subfolder has to be copied to R\bin\i386 and R\bin\x64 folder.
If you need to use the latest version of R for your own analysis, you can still make it. First, install the latest version of R as usual. Then install again the full-version of BRB-ArrayTools. This will possibly install another version of R and register it in the Windows's registry for BRB-ArrayTools to use. Now you can enjoy both versions of R as you want. The idea is when you install R, it will by default register R, but this behavior can break the setting for R to be used by BRB-ArrayTools. Once you install BRB-ArrayTools, it will install an R it needs and not erase any other versions of R you already have.
RExcel-statconnDCOM gave an error
Please upgrade BRB-ArrayTools to v4.3.x where Rserve has replaced statconnDCOM.
Rserve
Since version 4.3.0, BRB-ArrayTools started to use Rserve as a media for the communication between R and Excel. When Rserve is required, an R window will be pop up. This R window has a blue icon on the Windows' taskbar. If you accidentally close it, it will be automatically popped up when it is needed.
See my Rserve wiki page.
Importing
Multiple chips (hgu133a and hgu133b)
GSE4922 contains two different array platforms (hgu133a and hgu133b). Starting from ArrayTools v4.1 our software does not support the importing of multi-chips any more. Therefore you cannot directly import all the data into BRB-ArrayTools to create one project with two different chips. However, you could import the data into ArrayTools as two different projects and output the normalized data for each project. Then you can manually combine the two output data files and re-import into BRB-ArrayTools as one project. Here is what you can do,
- Use Data Import Wizard to import the CEL files for hgu133a and hgu133b chips separately to create two projects.
- Open each project and then use the "Export 1-color data to R" plug-in (click on "ArrayTools -> Plugins -> Export 1 color data to R") to output your normalized data file along with the GeneId file.
- Under Excel, combine the normalized output files ("NORMALIZEDLOGINTENSITY.txt") from two projects. Add sample names in the first row and Probe Set Ids in the first column. Save this combined data file. Then combine the two "GENEID.txt" files manually to create one Gene ID file.
- Open Excel, Click on "ArrayTools -> Import data -> General format importer" to import the combined data file. Select your data as "Single-channel", "Affymetrix probeset-summary data". For the chip type, because your data contain probe sets from both hgu133a and hgu133b, almost all of which were included in the hgu133plus2 chip, you can just pick the hgu133plus2 as your chip type. Alternatively, if you do not wish to do this, you can check "I would like to use my own gene identifiers file rather than the one from bioconductor" and use the combined Gene ID file (done in step 3) for annotation.
- At the filter and normalization step, it is VERY IMPORTANT that you need to uncheck all the spot filter and normalization options, because your "raw" data file comes from already normalized data in two different projects. You do not want to re-run normalization. You can keep the options in "Gene filter" tab.
- At the end you can run annotation as your choice.
PrimeView importing failed on v4.3.0 beta1 (R 2.14.x)
- Go to http://www.bioconductor.org/packages/2.11/data/annotation/html/primeviewcdf.html and click on the link for the windows binary package "primeviewcdf_2.11.0.zip" and download the zipped package.
- Unzip the downloaded package and put the entire package folder "primeviewcdf" under your R2.14.2 library folder (default C:\Program Files\R\R-2.14.2\library).
However, you cannot run Affymetrix annotation using bioconductor annotation packages at the end of importing, because the annotation package for primeview array is not available at bioconductor. Another commonly use annotation database, SOURCE, has also been down these days. Instead you need to import your own annotation into BRB-ArrayTools. Here is what you can do,
- Download the primeview annotation file in CSV format from Affymetrix website (https://www.affymetrix.com/user/login.jsp?toURL=/support/file_download.affx?onloadforward=/analysis/downloads/na32/ivt/PrimeView.na32.annot.csv.zip).
- Open the CSV format file in Excel and then save it as a tab-delimited .txt file.
- Import your data in CEL file format into BRB-ArrayTools through Data Import Wizard. During importing, you need to check the option "Import your own identifiers file to annotate your data" at the "Probe Set Id options" page, and then Click on "OK". At the next dialog form you need to select the radio button "The identifiers are stored in a separate file" and browse for the tab-delimited file you just saved. The head line # for this file is 25. Then you need to select the corresponding gene identifiers column headers. You need to check the box "Annotate the project with these gene ids, instead of using the data from SOURCE database" before proceeding to the next page.
Gene ST 1.1
Annotation
SOURCE at stanford is down
During the period of time when SOURCE website is down, our users will not be able to import annotations from SOURCE database. The bioconductor annotation packages will still work for users having Affymetrix or Illumina array data. For non-Affymetrix and non-Illumina chip users who are creating new projects, here are a couple of alternative solutions,
- If the user has an existing annotated project with an identical chip type to the project he/she is creating, he/she can import the annotations from the existing project. This can be done by clicking on 'ArrayTools -> Utilities -> Annotate the data -> Import annotations from an existing project';
- If the user has an annotation file available, during the process of importing, the user can choose to import annotations from this file. At the step of selecting Gene Identifiers, the user can browse for the Gene Identifiers file and check the option 'Annotate the project with these gene ids, instead of using the data from SOURCE database';
- If the user does not have an annotation file, for most commonly used commercial chips, the annotation files can be downloaded from GEO database at NCBI. For instance, the annotation file for the Agilent-014850 Whole Human Genome Microarray chip can be downloaded at http://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL4133 by clicking on the 'Download full table' button. This downloaded annotation file can then be imported into BRB-ArrayTools following step 2).
Gene ST array annotation using aroma.affymetrix
The aroma.affymetrix can handle all single-channel Affymetrix chip types (they have a few multi-channel ones not supported), so my guess is that it is already supported. What's required for nearly all aroma analysis, is to have a CDF annotation file that defines the units and unit groups, e.g. probe sets of transcripts and exons, SNPs and so on. When Affymetrix is not providing a CDF, the challenge is to either find a custom CDF (e.g. BrainArray and GeneAnnot) or to create a one from the other types of annotation data they or Bioconductor provide, e.g. http://aroma-project.org/howtos.
Analysis
Best parameter or analysis to choose
Ask your local help desk.
For affy cel files, GCRMA has a memory problem and MAS5 is way too slow
It is a known problem. BRB-ArrayTools uses justGCRMA() function in 'gcrma' package for GCRMA option and justMAS() function in 'simpleaffy' package for MAS5 option.
Quirks
- Do not place the project in a very deep path.
- Do not include special characters (single/double quote, percent sign, etc), in the project name, output name, column header in the experiment descriptor worksheet.
- Do not sort the experiment descriptor worksheet.
- R's impute package tends to crash R when the number of genes is small.
- R's pamr package failed when the number of genes is only one. The error message is
Error in rep(1, p) : invalid 'times' argument
It is a bug in pamr.train() -> nsc().
- Write the R file used in plugins in a conventional format.
Citing
Plugins Developers
Support
Send an email to [email protected]
Please provide enough information to us so we can understand the problem.
- If a bug report file was generated, be sure to send it to us.
- If the question is like 'what method or parameters should be choose to run my analysis', please consult other experienced people near you.
- Since the software depends on a couple factors like Windows operation system, MS-Office, R. Please provide us more detailed information about the software background including BRB-ArrayTools.
- When sending screenshots to us, please provide all error screenshots. If you only provide any random of them, it will create a misleading to us.
Check BRB-ArrayTools message board [1]
Developer's page
See developer's page link here.