PCA: Difference between revisions
| Line 193: | Line 193: | ||
par(omar) | par(omar) | ||
</pre> | </pre> | ||
[https:// | [https://rpkgs.datanovia.com/factoextra/reference/fviz_pca.html ? factoextra::fviz_pca_ind] | ||
<pre> | <pre> | ||
library(factoextra) | library(factoextra) | ||
| Line 199: | Line 199: | ||
habillage=iris$Species, | habillage=iris$Species, | ||
label = "none", | label = "none", | ||
addEllipses=TRUE) | addEllipses=TRUE, title = "PCA") | ||
</pre> | </pre> | ||
<li>[http://oracledmt.blogspot.com/2007/06/way-cooler-pca-and-visualization-linear.html PCA and Visualization] | <li>[http://oracledmt.blogspot.com/2007/06/way-cooler-pca-and-visualization-linear.html PCA and Visualization] | ||
Revision as of 15:56, 5 February 2024
Principal component analysis
What is PCA
- https://en.wikipedia.org/wiki/Principal_component_analysis
- StatQuest: Principal Component Analysis (PCA), Step-by-Step (video)
- StatQuest: PCA in R
- Using R for Multivariate Analysis
- How exactly does PCA work? What PCA (with SVD) does is, it finds the best fit line for these data points which minimizes the distance between the data points and their projections on the best fit line.
- What Is Principal Component Analysis (PCA) and How It Is Used? PCA creates a visualization of data that minimizes residual variance in the least squares sense and maximizes the variance of the projection coordinates.
- Principal Component Analysis: a brief intro for biologists
Linear Algebra
Linear Algebra for Data Science with examples in R
R source code
> stats:::prcomp.default
function (x, retx = TRUE, center = TRUE, scale. = FALSE, tol = NULL,
...)
{
x <- as.matrix(x)
x <- scale(x, center = center, scale = scale.)
cen <- attr(x, "scaled:center")
sc <- attr(x, "scaled:scale")
if (any(sc == 0))
stop("cannot rescale a constant/zero column to unit variance")
s <- svd(x, nu = 0)
s$d <- s$d/sqrt(max(1, nrow(x) - 1))
if (!is.null(tol)) {
rank <- sum(s$d > (s$d[1L] * tol))
if (rank < ncol(x)) {
s$v <- s$v[, 1L:rank, drop = FALSE]
s$d <- s$d[1L:rank]
}
}
dimnames(s$v) <- list(colnames(x), paste0("PC", seq_len(ncol(s$v))))
r <- list(sdev = s$d, rotation = s$v, center = if (is.null(cen)) FALSE else cen,
scale = if (is.null(sc)) FALSE else sc)
if (retx)
r$x <- x %*% s$v
class(r) <- "prcomp"
r
}
<bytecode: 0x000000003296c7d8>
<environment: namespace:stats>
rank of a matrix
R example
Principal component analysis (PCA) in R including bi-plot.
R built-in plot
http://genomicsclass.github.io/book/pages/pca_svd.html
pc <- prcomp(x) group <- as.numeric(tab$Tissue) plot(pc$x[, 1], pc$x[, 2], col = group, main = "PCA", xlab = "PC1", ylab = "PC2")
The meaning of colors can be found by palette().
- black
- red
- green3
- blue
- cyan
- magenta
- yellow
- gray
palmerpenguins data
Theory with an example
Principal Component Analysis in R: prcomp vs princomp
Biplot
- Biplots are everywhere: where do they come from?
- ggbiplot. Principal Component Analysis in R Tutorial from datacamp.
- Exploring Multivariate Data with Principal Component Analysis (PCA) Biplot in R
factoextra
- https://cran.r-project.org/web/packages/factoextra/index.html
- Factoextra R Package: Easy Multivariate Data Analyses and Elegant Visualization
Tips
Removing Zero Variance Columns
Efficiently Removing Zero Variance Columns (An Introduction to Benchmarking)
# Assume df is a data frame or a list (matrix is not enough!)
removeZeroVar3 <- function(df){
df[, !sapply(df, function(x) min(x) == max(x))]
}
# Assume df is a matrix
removeZeroVar3 <- function(df){
df[, !apply(df, 2, function(x) min(x) == max(x))]
}
# benchmark
dim(t(tpmlog)) # [1] 58 28109
system.time({a <- t(tpmlog); a <- a[, apply(a, 2, sd) !=0]}) # 0.54
system.time({a <- t(tpmlog); a <- removeZeroVar3(a)}) # 0.18
Removal of constant columns in R
Do not scale your matrix
https://privefl.github.io/blog/(Linear-Algebra)-Do-not-scale-your-matrix/
Apply the transformation on test data
- How to use PCA on test set (code)
- How to use R prcomp results for prediction?
- How to perform PCA in the validation/test set?
Calculated by Hand
http://strata.uga.edu/software/pdf/pcaTutorial.pdf
Variance explained by the first XX components
- StatQuest: Principal Component Analysis (PCA), Step-by-Step
- Singular Value Decomposition (SVD) Tutorial Using Examples in R
svd2 <- svd(Z) variance.explained <- prop.table(svd2$d^2)
OR
pr <- prcomp(USArrests, scale. = TRUE) # PS default is scale. = FALSE summary(pr) # Importance of components: # PC1 PC2 PC3 PC4 # Standard deviation 1.5749 0.9949 0.59713 0.41645 # Proportion of Variance 0.6201 0.2474 0.08914 0.04336 <------- # Cumulative Proportion 0.6201 0.8675 0.95664 1.00000 pr$sdev^2/ sum(pr$sdev^2) # [1] 0.62006039 0.24744129 0.08914080 0.04335752
Visualization
- Tutorial:Basic normalization, batch correction and visualization of RNA-seq data. log(CPM) was used.
- DESeq2 - PCAplot differs between rlog and vsd transformation. VST is the one to use or log2(count + 1), which can be performed with normTransform().
- ggfortify or the basic method
- PCA Visualization in ggplot2 - ggplot2::autoplot(). How To Make PCA Plot with R
- Difference ggplot2 and autoplot() after prcomp? In the autoplot method, the principal components are scaled. We can turn off the scaling by specifying "scale =0" in autoplot().
- Add ellipse - Difference ggplot2 and autoplot() after prcomp? (same post as above, use the basic method instead of autoplot()). We can also use factoextra package to draw a PCA plot with ellipses. Draw Ellipse Plot for Groups in PCA in R (2 Examples).
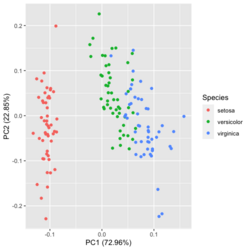
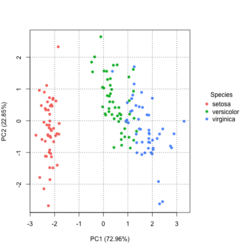
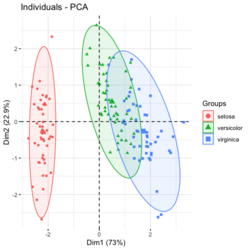
?ggfortify::autoplot.prcomplibrary(ggfortify) iris[1:2,] # Sepal.Length Sepal.Width Petal.Length Petal.Width Species # 1 5.1 3.5 1.4 0.2 setosa # 2 4.9 3.0 1.4 0.2 setosa df <- iris[1:4] # exclude "Species" column pca_res <- prcomp(df, scale. = TRUE) p <- autoplot(pca_res, data = iris, colour = 'Species') # OR turn off scaling on axes in order to get the same plot as the direct method # p <- autoplot(pca_res, data = iris, colour = 'Species', scale = 0) p # PC1 (72.96%), PC2 (22.85%) library(plotly) ggplotly(p)
Basic method
group <- as.numeric(iris$Species) # ggplot2's palette gg_color_hue <- function(n) { hues = seq(15, 375, length = n + 1) hcl(h = hues, l = 65, c = 100)[1:n] } n <- 3 # iris$Species has 3 levels cols = gg_color_hue(n) prp <- pca_res$sdev^2/ sum(pca_res$sdev^2) xlab <- paste0("PC1 (", round(prp[1]*100,2), "%)") ylab <- paste0("PC2 (", round(prp[2]*100,2), "%)") omar <- par(mar=c(5,4,4,8)) plot(pca_res$x[, 1], pca_res$x[, 2], xlab = xlab, ylab = ylab, col = cols[group], pch=16) grid(NULL, NULL, lty=3, lwd=1, col="#000000") par(xpd=TRUE) legend(4, 1, legend = levels(iris$Species), col=cols, pch=16, bty = "n", title = "Species") par(xpd=FALSE) par(omar)library(factoextra) fviz_pca_ind(pca_res, habillage=iris$Species, label = "none", addEllipses=TRUE, title = "PCA") - PCA and Visualization
- Scree plots from the FactoMineR package (based on ggplot2)
- 2 lines of code, plotPCA() from DESeq2



Interactive Principal Component Analysis
- Use the identify() function and mouse clicks to label some points (also return the indices of these points).
- Interactive Principal Component Analysis in R
center and scale
What does it do if we choose center=FALSE in prcomp()?
In USArrests data, use center=FALSE gives a better scatter plot of the first 2 PCA components.
x1 = prcomp(USArrests) x2 = prcomp(USArrests, center=F) plot(x1$x[,1], x1$x[,2]) # looks random windows(); plot(x2$x[,1], x2$x[,2]) # looks good in some sense
"scale. = TRUE" and Mean subtraction
- PCA is sensitive to the scaling of the variables. See PCA -> Further considerations.
- https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/prcomp
- By default scale. = FALSE in prcomp()
- By default, it centers the variable to have mean equals to zero. With parameter scale. = T, we normalize the variables to have standard deviation equals to 1. See also Normalizing all the variarbles vs. using scale=TRUE option in prcomp in R.
- Practical Guide to Principal Component Analysis (PCA) in R & Python
- What is the best way to scale parameters before running a Principal Component Analysis (PCA)?
- As a rule of thumb, if all your variables are measured on the same scale and have the same unit, it might be a good idea *not* to scale the variables (i.e., PCA based on the covariance matrix). If you want to maximize variation, it is fair to let variables with more variation contribute more. On the other hand, If you have different types of variables with different units, it is probably wise to scale the data first (i.e., PCA based on the correlation matrix).
- If all your variables are recorded in the same scale and/or the difference in variable magnitudes are of interest, you may choose not to normalize your data prior to PCA. See Normalizing all the variarbles vs. using scale=TRUE option in prcomp in R
- Let's compare the difference using the USArrests data
USArrests[1:3,] # Murder Assault UrbanPop Rape # Alabama 13.2 236 58 21.2 # Alaska 10.0 263 48 44.5 # Arizona 8.1 294 80 31.0 pca1 <- prcomp(USArrests) # inappropriate, default is scale. = FALSE pca2 <- prcomp(USArrests, scale. = TRUE) pca1$x[1:3, 1:3] # PC1 PC2 PC3 # Alabama 64.80216 -11.448007 -2.494933 # Alaska 92.82745 -17.982943 20.126575 # Arizona 124.06822 8.830403 -1.687448 pca2$x[1:3, 1:3] # PC1 PC2 PC3 # Alabama -0.9756604 1.1220012 -0.43980366 # Alaska -1.9305379 1.0624269 2.01950027 # Arizona -1.7454429 -0.7384595 0.05423025 set.seed(1) X <- matrix(rnorm(10*100), nr=10) pca1 <- prcomp(X) pca2 <- prcomp(X, scale. = TRUE) range(abs(pca1$x - pca2$x)) # [1] 3.764350e-16 1.139182e+01 par(mfrow=c(1,2)) plot(pca1$x[,1], pca1$x[, 2], main='scale=F') plot(pca2$x[,1], pca2$x[, 2], main='scale=T') par(mfrow=c(1,1)) # rotation matrices are different # sdev are different # rotation matrices are different # Same observations for a long matrix too set.seed(1) X <- matrix(rnorm(10*100), nr=100) pca1 <- prcomp(X) pca2 <- prcomp(X, scale. = TRUE) range(abs(pca1$x - pca2$x)) # [1] 0.001915974 5.112158589 svd1 <- svd(USArrests) svd2 <- svd(scale(USArrests, F, T)) svd1$d # [1] 1419.06140 194.82585 45.66134 18.06956 svd2$d # [1] 13.560545 2.736843 1.684743 1.335272 # u (or v) are also different
- Biplot
Number of components
Obtaining the number of components from cross validation of principal components regression
AIC/BIC in estimating the number of components
PCA and SVD
Using the SVD to perform PCA makes much better sense numerically than forming the covariance matrix to begin with, since the formation of [math]\displaystyle{ X X^T }[/math] can cause loss of precision.
- http://math.stackexchange.com/questions/3869/what-is-the-intuitive-relationship-between-svd-and-pca
- Relationship between SVD and PCA. How to use SVD to perform PCA?
R example
covMat <- matrix(c(4, 0, 0, 1), nr=2)
p <- 2
n <- 1000
set.seed(1)
x <- mvtnorm::rmvnorm(n, rep(0, p), covMat)
svdx <- svd(x)
result= prcomp(x, scale = TRUE)
summary(result)
# Importance of components:
# PC1 PC2
# Standard deviation 1.0004 0.9996
# Proportion of Variance 0.5004 0.4996
# Cumulative Proportion 0.5004 1.0000
# It seems scale = FALSE result can reflect the original data
result2 <- prcomp(x, scale = FALSE) # DEFAULT
summary(result2)
# Importance of components:
# PC1 PC2
# Standard deviation 2.1332 1.0065 ==> Close to the original data
# ==> How to compute
# sqrt(eigen(var(x))$values ) = 2.133203 1.006460
# Proportion of Variance 0.8179 0.1821 ==> How to verify
# 2.1332^2/(2.1332^2+1.0065^2) = 0.8179
# Cumulative Proportion 0.8179 1.0000
result2$sdev
# 2.133203 1.006460 # sqrt( SS(distance)/(n-1) )
result2$sdev^2 / sum(result2$sdev^2)
# 0.8179279 0.1820721
result2$rotation
# PC1 PC2
# [1,] 0.9999998857 -0.0004780211
# [2,] -0.0004780211 -0.9999998857
result2$sdev^2 * (n-1)
# [1] 4546.004 1011.948 # SS(distance)
# eigenvalue for PC1 = singular value^2
svd(scale(x, center=T, scale=F))$d
# [1] 67.42406 31.81113
svd(scale(x, center=T, scale=F))$d ^ 2 # SS(distance)
# [1] 4546.004 1011.948
svd(scale(x, center=T, scale=F))$d / sqrt(nrow(x) -1)
# [1] 2.133203 1.006460 ==> This is the same as prcomp()$sdev
svd(scale(x, center=F, scale=F))$d / sqrt(nrow(x) -1)
# [1] 2.135166 1.006617 ==> So it does not matter to center or scale
svd(var(x))$d
# [1] 4.550554 1.012961
svd(scale(x, center=T, scale=F))$v # same as result2$rotation
# [,1] [,2]
# [1,] 0.9999998857 -0.0004780211
# [2,] -0.0004780211 -0.9999998857
sqrt(eigen(var(x))$values )
# [1] 2.133203 1.006460
eigen(t(scale(x,T,F)) %*% scale(x,T,F))$values # SS(distance)
# [1] 4546.004 1011.948
sqrt(eigen(t(scale(x,T,F)) %*% scale(x,T,F))$values ) # Same as svd(scale(x.T,F))$d
# [1] 67.42406 31.81113.
# So SS(distance) = eigen(t(scale(x,T,F)) %*% scale(x,T,F))$values
# = svd(scale(x.T,F))$d ^ 2
Related to Factor Analysis
- http://www.aaronschlegel.com/factor-analysis-introduction-principal-component-method-r/.
- http://support.minitab.com/en-us/minitab/17/topic-library/modeling-statistics/multivariate/principal-components-and-factor-analysis/differences-between-pca-and-factor-analysis/
In short,
- In Principal Components Analysis, the components are calculated as linear combinations of the original variables. In Factor Analysis, the original variables are defined as linear combinations of the factors.
- In Principal Components Analysis, the goal is to explain as much of the total variance in the variables as possible. The goal in Factor Analysis is to explain the covariances or correlations between the variables.
- Use Principal Components Analysis to reduce the data into a smaller number of components. Use Factor Analysis to understand what constructs underlie the data.
prcomp vs princomp
prcomp vs princomp from sthda. prcomp() is preferred compared to princomp().
Missing data
Relation to Multidimensional scaling/MDS
With no missing data, classical MDS (Euclidean distance metric) is the same as PCA.
Comparisons are here.
Differences are asked/answered on stackexchange.com. The post also answered the question when these two are the same.
isoMDS (Non-metric)
cmdscale (Metric)
Matrix factorization methods
http://joelcadwell.blogspot.com/2015/08/matrix-factorization-comes-in-many.html Review of principal component analysis (PCA), K-means clustering, nonnegative matrix factorization (NMF) and archetypal analysis (AA).
Outlier samples
Detecting outlier samples in PCA
Reconstructing images
Reconstructing images using PCA
Sparse PCA
- https://en.wikipedia.org/wiki/Sparse_PCA
- 8.6.1 Sparse Principal Components from Harrell's "Regression Modeling Strategies" book
- pcaPP package
Misc
PCA for Categorical Variables
- FAMD - Factor Analysis of Mixed Data in R: Essentials
- PCA for Categorical Variables in R. Factorial Analysis of Mixed Data (FAMD) Is a PCA for Categorical Variables Alternate.
psych package
Principal component analysis (PCA) in R
glmpca: Generalized PCA for dimension reduction of sparse counts
Feature selection and dimension reduction for single-cell RNA-Seq based on a multinomial model